Audio_DAR
Do audio features improve dialogue act classification?
Do Audio Features Improve Dialogue Act Classification?
Research on impact of audio features on multi-label Dialogue Act Classification (DAC).
Motivation
Dialogue Act Classification lies at the bases of most dialogue systems like voice assistants etc.
Separate text-based DAC and Automatic Speech Recognition (ASR) is a standard practice prone to errors, due to imperfect ASR models.
Having audio present in such real-life scenarios opens up possibilities for improving classification via deeper integration of those, traditionally separated, modules.
Examining the impact of audio features is also crucial for deeper understanding of human communication.
Data
- SLUE HVB - base dataset - new, unexplored and challenging, due to its multi-label nature, benchmark
- Extracted audio encodings using Whisper model
- Extracted audio features in 25ms frames using own implementation
Models overview
20 models were trained and evaluated (both E2E and GT) on SLUE HVB dataset using different combinations of modules explained below.
Sentence representation
Most models used simplified self-attention pooling to extract sentence representation, which is effectively dynamic weighted mean. Only exception is text based Phi 3 mini, where statically weighted mean worked best.

(Yes, it should be simplified to matmul).
Text based
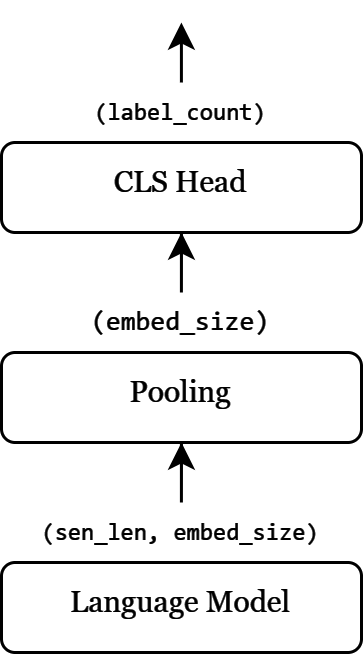
Cross attention
Stacked cross attention with residual connections and layer norms between text and audio encodings.
- Between text encoding and ASR encoder output
- Between text encoding and prosody encoder output ( transformer encoder)

Fusion
Stacked fusion of cross attentions with residual connections and layer norms between text and different audio encodings.


Results
Deeper analysis performed in my thesis (TBA), but here are some highlights.
Difference between Phi 3 mini and DistilBERT is not significant in overall metrics, but improvements can be seen on slightly different set of classes.
Model fusion_gttbsc_distilbert-uncased-best, along couple others, achieved State-of-the-Art results (to best of my knowledge) both on End-2-End (71.72 F1-macro) and Ground Truth (73.48 F1-macro) task on SLUE HVB dataset.
Fusion - Phi 3

Impact of ASR encoder on E2E task using Phi 3
Model learns ASR errors without any fine-tuning of backbones (E2E 72.04, GT 72.17 F1-macro).

Difference between text based and fusion using Phi 3

Impact of audio energy using DistilBERT

Impact of audio pitch using DistilBERT

Try it out
![]()
Using code from github you may load and test some predefined models yourself on End-2-End task, which is just audio classification.
# Optional config
%env LOG_LEVEL=INFO
%env LOG_DIR=../logs
%env HF_TOKEN=<HUGGINGFACE TOKEN>
%env HF_WRITE_PERMISSION=False
%env SAMPLE_RATE=16000
%env HF_HUB_DISABLE_SYMLINKS_WARNING=True
Load some models from my repo.
from model.pipelines import SingleEmbeddingPipeline, CrossAttentionPipeline, FusionPipeline
from config.datasets_config import SLUE_ID_2_LABEL
from model.single_embedding_dac import SingleEmbeddingSentenceClassifier
from model.cross_attention_dac import CrossAttentionSentenceClassifier
from model.fusion_attention_dac import FusionCrossAttentionSentenceClassifier
from config.datasets_config import Dataset
from utils.datasets import get
from transformers import AutoTokenizer
from transformers import WhisperProcessor
from audio.features import AudioFeatures
# tokenizers and audio processors
audio_processor = WhisperProcessor.from_pretrained("openai/whisper-small.en")
tokenizer = AutoTokenizer.from_pretrained('distilbert/distilbert-base-uncased')
# get some models
model_gt = SingleEmbeddingSentenceClassifier.from_pretrained('Masioki/gttbsc_distilbert-freezed-best',
load_on_init=False)
model_pros = CrossAttentionSentenceClassifier.from_pretrained('Masioki/prosody_gttbsc_distilbert-uncased-best',
load_on_init=True)
model_enc = CrossAttentionSentenceClassifier.from_pretrained('Masioki/enc-gtsc_distilbert-freezed', load_on_init=False)
model_f = FusionCrossAttentionSentenceClassifier.from_pretrained('Masioki/fusion_gttbsc_distilbert-uncased-best',
load_k2_on_init=True)
# load sample from dataset
ds = get(Dataset.SLUE_HVB)
sample = ds['test'][0]
Use custom audio classification with transcription piplines.
# Text model
pipe = SingleEmbeddingPipeline(
model=model_gt,
audio_processor=audio_processor,
text_tokenizer=tokenizer,
sampling_rate=sample['audio']['sampling_rate'],
id_2_label=SLUE_ID_2_LABEL
)
# pipe("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac")
print(sample['dialog_acts'])
pipe(sample['audio']['array'])
# ['question_general', 'statement_open']
# (['question_general', 'statement_open'],
# ' Hello, this is Harper Valley National Bank. My name is Michael. How can I help you today?')
# Prosody with text model
pipe = CrossAttentionPipeline(
model=model_pros,
audio_processor=audio_processor,
text_tokenizer=tokenizer,
sampling_rate=sample['audio']['sampling_rate'],
id_2_label=SLUE_ID_2_LABEL,
audio_features=[
AudioFeatures.LOG_PITCH_POV,
AudioFeatures.LOG_PITCH_DER,
AudioFeatures.LOG_TOTAL_E,
AudioFeatures.LOG_TOTAL_E_LOWER_BANDS,
AudioFeatures.LOG_TOTAL_E_UPPER_BANDS
]
)
print(sample['dialog_acts'])
pipe(sample['audio']['array'])
# ['question_general', 'statement_open']
# (['question_general', 'statement_open', 'statement_problem'],
# ' Hello, this is Harper Valley National Bank. My name is Michael. How can I help you today?')
# ASR encodings with text model
pipe = CrossAttentionPipeline(
model=model_enc,
audio_processor=audio_processor,
text_tokenizer=tokenizer,
sampling_rate=sample['audio']['sampling_rate'],
id_2_label=SLUE_ID_2_LABEL,
)
print(sample['dialog_acts'])
pipe(sample['audio']['array'])
# ['question_general', 'statement_open']
# (['question_general', 'statement_open'],
# ' Hello, this is Harper Valley National Bank. My name is Michael. How can I help you today?')
# Fusion model
pipe = FusionPipeline(
model=model_f,
audio_processor=audio_processor,
text_tokenizer=tokenizer,
sampling_rate=sample['audio']['sampling_rate'],
id_2_label=SLUE_ID_2_LABEL,
audio_features=[
AudioFeatures.LOG_PITCH_POV,
AudioFeatures.LOG_PITCH_DER,
AudioFeatures.LOG_TOTAL_E,
AudioFeatures.LOG_TOTAL_E_LOWER_BANDS,
AudioFeatures.LOG_TOTAL_E_UPPER_BANDS
]
)
print(sample['dialog_acts'])
pipe(sample['audio']['array'])
# ['question_general', 'statement_open']
# (['question_general', 'statement_open'],
# ' Hello, this is Harper Valley National Bank. My name is Michael. How can I help you today?')
Poster
Poster presented at AI Forum 2024 - Wrocław University of Science and Technology.
